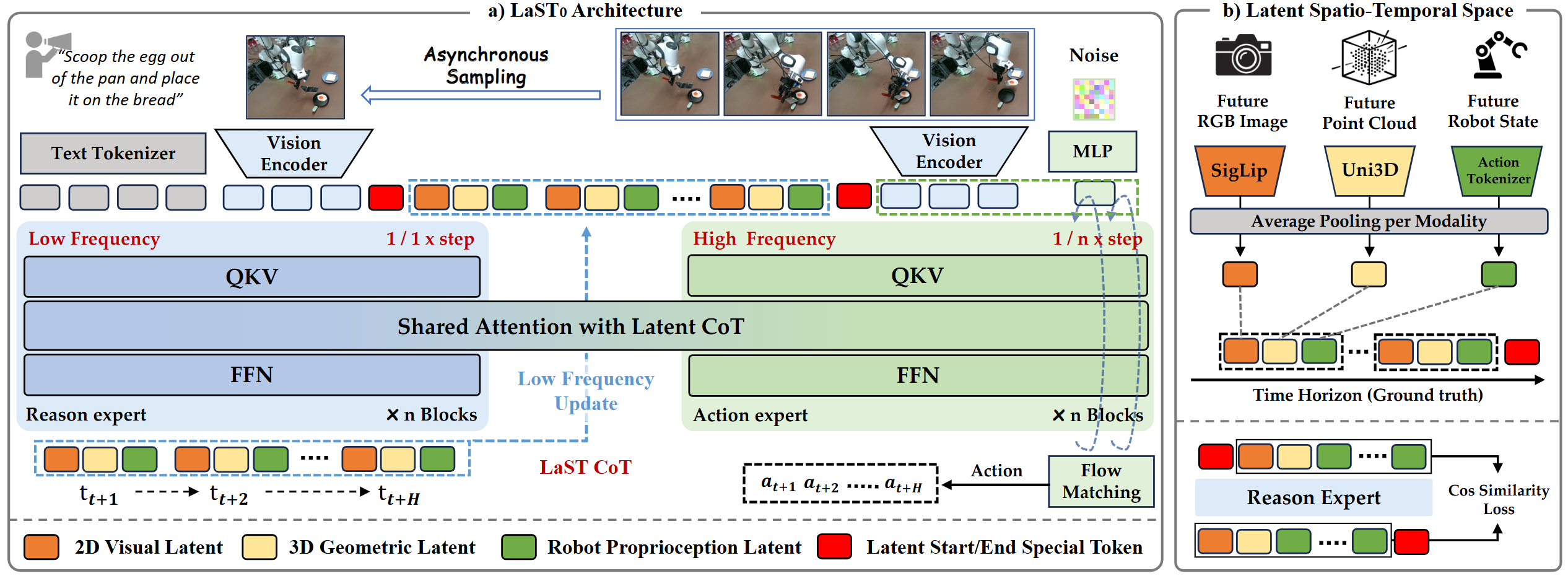
Vision-Language-Action (VLA) models have recently shown strong generalization, with some approaches seeking to explicitly generate linguistic reasoning traces or predict future observations prior to execution. However, explicit reasoning typically incurs non-negligible inference latency, which constrains the temporal resolution required for robotic manipulation. Moreover, such reasoning is confined to the linguistic space, imposing a representational bottleneck that struggles to faithfully capture ineffable physical attributes. To mitigate these limitations, we propose LaST0, a framework that enables efficient reasoning before acting through a Latent Spatio-Temporal Chain-of-Thought (CoT), capturing fine-grained physical and robotic dynamics that are often difficult to verbalize. Specifically, we introduce a token-efficient latent CoT space that models future visual dynamics, 3D structural information, and robot proprioceptive states, and further extends these representations across time to enable temporally consistent implicit reasoning trajectories. Furthermore, LaST0 adopts a dual-system architecture implemented via a Mixture-of-Transformers design, where a reasoning expert conducts low-frequency latent inference and an acting expert generates high-frequency actions conditioned on robotics-oriented latent representations. To facilitate coordination, LaST0 is trained with heterogeneous operation frequencies, enabling adaptive switching during deployment. Across 10 real-world tasks spanning tabletop, mobile, and dexterous hand manipulation, LaST0 improves mean success rates by 13%, 14% and 14% over prior SOTA VLA methods, respectively.
All tasks are trained and tested with keyframes
Wipe the whiteboard
Press stamp on paper
Put dish on rack
Place egg on bread (long horizon)
Scoop popcorn into a bowl
Open pot pick corn
Arrange dishes
Sort spoons
Open drawer
Place button
@misc{liu2026last0latentspatiotemporalchainofthought,
title={LaST$_{0}$: Latent Spatio-Temporal Chain-of-Thought for Robotic Vision-Language-Action Model},
author={Zhuoyang Liu and Jiaming Liu and Hao Chen and Ziyu Guo and Chengkai Hou and Chenyang Gu and Jiale Yu and Xiangju Mi and Renrui Zhang and Zhengping Che and Jian Tang and Pheng-Ann Heng and Shanghang Zhang},
year={2026},
eprint={2601.05248},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2601.05248},
}